UPDATE
In May of 2021 I co-wrote pwiser a package for doing pairwise operations in {dplyr} that provides a much smoother approach than the one I build-up to in this post.
Overview
Say you want to map an operation or list of operations across all two-way1 combinations of a set of variables/columns in a dataframe. For example, you may be doing feature engineering and want to create a set of interaction terms, ratios, etc2. You may be interested in computing a summary statistic across all pairwise combinations of a given set of variables3. In some cases there may be a pairwise implementation already available, e.g. R’s cor() function for computing correlations4. In other cases one may not exist or is not easy to use5. In this post I’ll walk through an example6 explaining code and steps for setting-up arbitrary pairwise operations across sets of variables.
I’ll break my approach down into several steps:
I. Nest and pivot
II. Expand combinations
III. Filter redundancies
IV. Map function(s)
V. Return to normal dataframe
VI. Bind back to data
If your interest is only in computing summary statistics (as opposed to modifying an existing dataframe with new columns / features), then only steps I - IV are needed.
Relevant software and style:
I will primarily be using R’s tidyverse packages. I make frequent use of lists as columns within dataframes – if you are new to these, see my previous talk and the resources7 I link to in the description.
Throughout this post, wherever I write “dataframe” I really mean “tibble” (a dataframe with minor changes to default options and printing behavior). Also note that I am using dplyr 0.8.3 rather than the newly released 1.0.08.
Other resources and open issues (updated 2020-06-14):
In particular, the comments in issue 44 for the corrr package contain excellent solutions for doing pairwise operations (the subject of this post)9. Issue 94 also features discussion on this topic. Throughout this post I will reference other alternative code/approaches (especially in the footnotes and the Appendix).
Data:
I’ll use the ames housing dataset across examples.
ames <- AmesHousing::make_ames()Specifically, I’ll focus on ten numeric columns that, based on a random sample of 1000 rows, show the highest correlation with Sale_Price10.
library(tidyverse)
set.seed(2020)
ames_cols <- ames %>%
select_if(is.numeric) %>%
sample_n(1000) %>%
corrr::correlate() %>%
corrr::focus(Sale_Price) %>%
arrange(-abs(Sale_Price)) %>%
head(10) %>%
pull(term)
ames_subset <- select(ames, ames_cols) %>%
# Could normalize data or do other prep
# but is not pertinent for examples
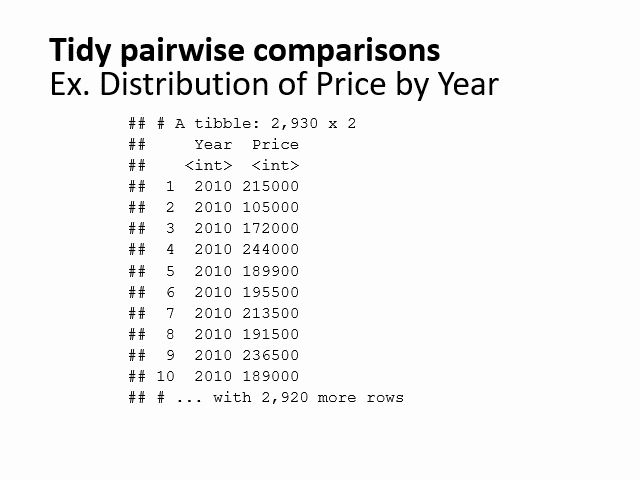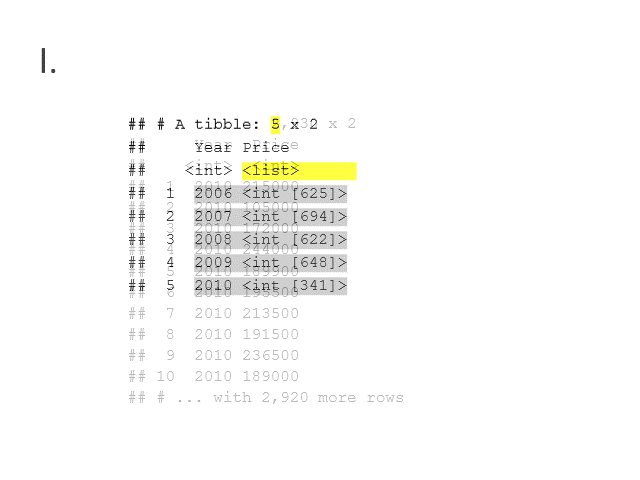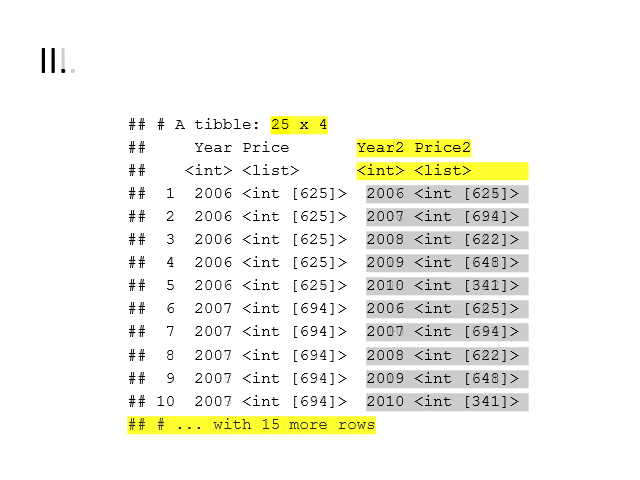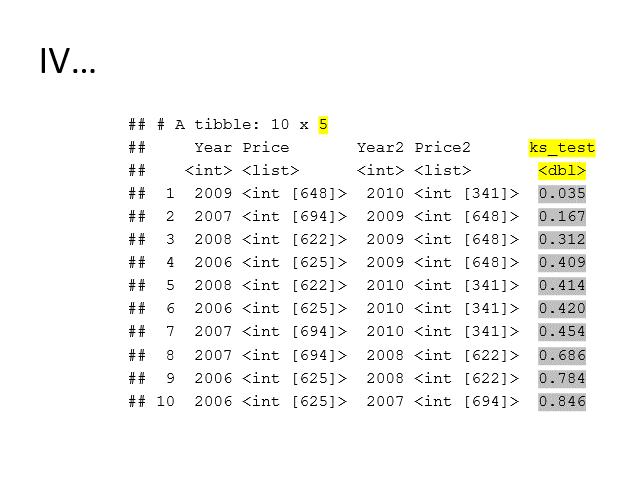
mutate_all(as.double)I. Nest and pivot
There are a variety of ways to make lists into columns within a dataframe. In the example below, I first use summarise_all(.tbl = ames_subset, .funs = list) to create a one row dataframe where each column is a list containing a single element and each individual element corresponds with a numeric vector of length 2930.
After nesting, I pivot11 the columns leaving a dataframe with two columns:
varthe variable namesvectora list where each element contains the associated vector
df_lists <- ames_subset %>%
summarise_all(list) %>%
pivot_longer(cols = everything(),
names_to = "var",
values_to = "vector") %>%
print()## # A tibble: 10 x 2
## var vector
## <chr> <list>
## 1 Gr_Liv_Area <dbl [2,930]>
## 2 Garage_Cars <dbl [2,930]>
## 3 Garage_Area <dbl [2,930]>
## 4 Total_Bsmt_SF <dbl [2,930]>
## 5 First_Flr_SF <dbl [2,930]>
## 6 Year_Built <dbl [2,930]>
## 7 Full_Bath <dbl [2,930]>
## 8 Year_Remod_Add <dbl [2,930]>
## 9 TotRms_AbvGrd <dbl [2,930]>
## 10 Fireplaces <dbl [2,930]>See Pivot and then summarise for a nearly identical approach with just an altered order of steps. Also see Nested tibbles for how you could create a list-column of dataframes12 rather than vectors.
What if my variables are across rows not columns?
For example, pretend you want to see if Sale_Price is different across Mo_Sold. Perhaps you started by doing an F-test, found that to be significant, and now want to do pairwise t-tests across the samples of Sale_Price for each Mo_Sold. To set this up, you will want a group_by() rather than a pivot_longer() step. E.g.
ames %>%
group_by(Mo_Sold) %>%
summarise(Sale_Price = list(Sale_Price)) ## # A tibble: 12 x 2
## Mo_Sold Sale_Price
## <int> <list>
## 1 1 <int [123]>
## 2 2 <int [133]>
## 3 3 <int [232]>
## 4 4 <int [279]>
## 5 5 <int [395]>
## 6 6 <int [505]>
## 7 7 <int [449]>
## 8 8 <int [233]>
## 9 9 <int [161]>
## 10 10 <int [173]>
## 11 11 <int [143]>
## 12 12 <int [104]>At which point your data is in fundamentally the same form as was created in the previous code chunk (at least for if we only care about computing summary metrics that don’t require vectors of equal length13) so you can move onto II. Expand combinations.
If the variables needed for your combinations of interest are across both rows and columns, you may want to use both pivot_longer() and group_by() steps and may need to make a few small modifications.
II. Expand combinations
I then use tidyr::nesting() within tidyr::expand() to make all 2-way combinations of our rows.
df_lists_comb <- expand(df_lists,
nesting(var, vector),
nesting(var2 = var, vector2 = vector)) %>%
print()## # A tibble: 100 x 4
## var vector var2 vector2
## <chr> <list> <chr> <list>
## 1 Fireplaces <dbl [2,930]> Fireplaces <dbl [2,930]>
## 2 Fireplaces <dbl [2,930]> First_Flr_SF <dbl [2,930]>
## 3 Fireplaces <dbl [2,930]> Full_Bath <dbl [2,930]>
## 4 Fireplaces <dbl [2,930]> Garage_Area <dbl [2,930]>
## 5 Fireplaces <dbl [2,930]> Garage_Cars <dbl [2,930]>
## 6 Fireplaces <dbl [2,930]> Gr_Liv_Area <dbl [2,930]>
## 7 Fireplaces <dbl [2,930]> Total_Bsmt_SF <dbl [2,930]>
## 8 Fireplaces <dbl [2,930]> TotRms_AbvGrd <dbl [2,930]>
## 9 Fireplaces <dbl [2,930]> Year_Built <dbl [2,930]>
## 10 Fireplaces <dbl [2,930]> Year_Remod_Add <dbl [2,930]>
## # ... with 90 more rowsSee Expand via join for an alternative approach using the dplyr::*_join() operations.
You could make a strong case that this step should be after III. Filter redundancies14. However putting it beforehand makes the required code easier to write and to read.
III. Filter redundancies
Filter-out redundant columns, sort the rows, better organize the columns.
df_lists_comb <- df_lists_comb %>%
filter(var != var2) %>%
arrange(var, var2) %>%
mutate(vars = paste0(var, ".", var2)) %>%
select(contains("var"), everything()) %>%
print()## # A tibble: 90 x 5
## var var2 vars vector vector2
## <chr> <chr> <chr> <list> <list>
## 1 Fireplaces First_Flr_SF Fireplaces.First_Flr_SF <dbl [2,930]> <dbl [2,~
## 2 Fireplaces Full_Bath Fireplaces.Full_Bath <dbl [2,930]> <dbl [2,~
## 3 Fireplaces Garage_Area Fireplaces.Garage_Area <dbl [2,930]> <dbl [2,~
## 4 Fireplaces Garage_Cars Fireplaces.Garage_Cars <dbl [2,930]> <dbl [2,~
## 5 Fireplaces Gr_Liv_Area Fireplaces.Gr_Liv_Area <dbl [2,930]> <dbl [2,~
## 6 Fireplaces Total_Bsmt_SF Fireplaces.Total_Bsmt_SF <dbl [2,930]> <dbl [2,~
## 7 Fireplaces TotRms_AbvGrd Fireplaces.TotRms_AbvGrd <dbl [2,930]> <dbl [2,~
## 8 Fireplaces Year_Built Fireplaces.Year_Built <dbl [2,930]> <dbl [2,~
## 9 Fireplaces Year_Remod_Add Fireplaces.Year_Remod_Add <dbl [2,930]> <dbl [2,~
## 10 First_Flr_SF Fireplaces First_Flr_SF.Fireplaces <dbl [2,930]> <dbl [2,~
## # ... with 80 more rowsIf your operation of interest is associative15, apply a filter to remove additional redundant combinations.
c_sort_collapse <- function(...){
c(...) %>%
sort() %>%
str_c(collapse = ".")
}
df_lists_comb_as <- df_lists_comb %>%
mutate(vars = map2_chr(.x = var,
.y = var2,
.f = c_sort_collapse)) %>%
distinct(vars, .keep_all = TRUE)IV. Map function(s)
Each row of your dataframe now contains the relevant combinations of variables and is ready to have any arbitrary function(s) mapped across them.
Example with summary statistic16:
For example, let’s say we want to compute the p-value of the correlation coefficient for each pair17.
pairs_cor_pvalues <- df_lists_comb_as %>%
mutate(cor_pvalue = map2(vector, vector2, cor.test) %>% map_dbl("p.value"),
vars = fct_reorder(vars, -cor_pvalue)) %>%
arrange(cor_pvalue) %>%
print()## # A tibble: 45 x 6
## var var2 vars vector vector2 cor_pvalue
## <chr> <chr> <fct> <list> <list> <dbl>
## 1 First_Flr_SF Total_Bsmt_SF First_Flr_SF.Tot~ <dbl [2,~ <dbl [2,9~ 0
## 2 Full_Bath Gr_Liv_Area Full_Bath.Gr_Liv~ <dbl [2,~ <dbl [2,9~ 0
## 3 Garage_Area Garage_Cars Garage_Area.Gara~ <dbl [2,~ <dbl [2,9~ 0
## 4 Gr_Liv_Area TotRms_AbvGrd Gr_Liv_Area.TotR~ <dbl [2,~ <dbl [2,9~ 0
## 5 Year_Built Year_Remod_Add Year_Built.Year_~ <dbl [2,~ <dbl [2,9~ 7.85e-301
## 6 First_Flr_SF Gr_Liv_Area First_Flr_SF.Gr_~ <dbl [2,~ <dbl [2,9~ 8.17e-244
## 7 Garage_Cars Year_Built Garage_Cars.Year~ <dbl [2,~ <dbl [2,9~ 1.57e-219
## 8 Full_Bath TotRms_AbvGrd Full_Bath.TotRms~ <dbl [2,~ <dbl [2,9~ 1.24e-210
## 9 First_Flr_SF Garage_Area First_Flr_SF.Gar~ <dbl [2,~ <dbl [2,9~ 8.16e-178
## 10 Garage_Cars Gr_Liv_Area Garage_Cars.Gr_L~ <dbl [2,~ <dbl [2,9~ 4.80e-175
## # ... with 35 more rowsFor fun, let’s plot the most significant associations onto a bar graph.
pairs_cor_pvalues %>%
head(15) %>%
mutate(cor_pvalue_nlog = -log(cor_pvalue)) %>%
ggplot(aes(x = vars,
y = cor_pvalue_nlog,
fill = is.infinite(cor_pvalue_nlog) %>% factor(c(T, F))))+
geom_col()+
coord_flip()+
theme_bw()+
labs(title = "We are confident that garage area and # of garage cars are correlated",
y = "Negative log of p-value of correlation coefficient",
x = "Variable combinations",
fill = "Too high to\nmeaningfully\ndifferentiate:")+
theme(plot.title.position = "plot")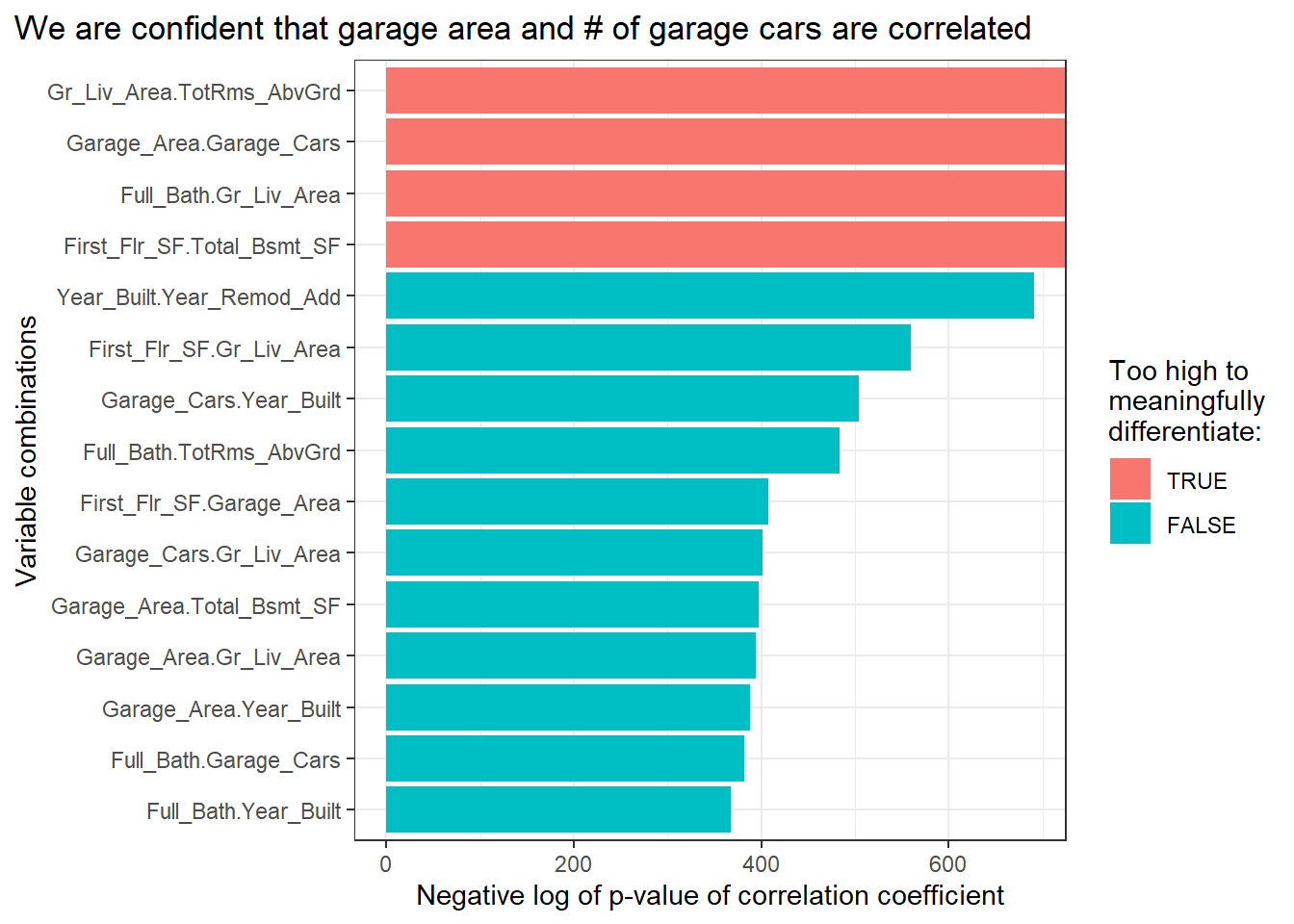
You could use this approach to calculate any pairwise summary statistic. For example, see gist where I calculate the K-S statistic across each combination of a group of distributions.
If you only care about computing summary statistics on your pairwise combinations, (and not adding new columns onto your original dataframe) you can stop here.
Example with transformations18:
Back to the feature engineering example, perhaps we want to create new features of the difference and quotient of each combination of our variables.
new_features_prep1 <- df_lists_comb %>%
mutate(difference = map2(vector, vector2, `-`),
ratio = map2(vector, vector2, `/`))V. Return to normal dataframe
The next set of steps will put our data back into a more traditional form consistent with our starting dataframe/tibble.
First let’s revert our data to a form similar to where it was at the end of I. Nest and pivot where we had two columns:
- one with our variable names
- a second containing a list-column of vectors
new_features_prep2 <- new_features_prep1 %>%
pivot_longer(cols = c(difference, ratio)) %>% # 1
mutate(name_vars = str_c(var, name, var2, sep = ".")) %>% # 2
select(name_vars, value) # 3At the end of each line of code above is a number corresponding with the following explanations:
- if we had done just one operation, this step would not be needed, but we did multiple operations, created multiple list-columns (
differenceandratio) which we need to get into a single list-column - create new variable name that combines constituent variable names with name of transformation
- remove old columns
Next we simply apply the inverse of those operations performed in I. Nest and pivot.
new_features <- new_features_prep2 %>%
pivot_wider(values_from = value,
names_from = name_vars) %>%
unnest(cols = everything())The new features will add a good number of columns onto our original dataset19.
dim(new_features)## [1] 2930 180VI. Bind back to data
I then bind the new features back onto the original subsetted dataframe.
ames_data_features <- bind_cols(ames_subset, new_features)At which point I could do further exploring, feature engineering, model building, etc.
Functionalize
I put these steps into a few (unpolished) functions found at this gist20.
devtools::source_gist("https://gist.github.com/brshallo/f92a5820030e21cfed8f823a6e1d56e1")mutate_pairwise() takes in your dataframe, the set of numeric columns to create pairwise combinations from, and a list of functions21 to apply.
Example creating & evaluating features
Let’s use the new mutate_pairwise() function to create new columns for the differences and quotients between all pairwise combinations of our variables of interest.
ames_data_features_example <- mutate_pairwise(
df = mutate_if(ames, is.numeric, as.double),
one_of(ames_cols),
funs = list("/", "-"),
funs_names = list("ratio", "difference"),
associative = FALSE
)Perhaps you want to calculate some measure of association between your features and a target of interest. To keep things simple, I’ll remove any columns that contain any NA’s or infinite values.
features_keep <- ames_data_features_example %>%
keep(is.numeric) %>%
keep(~sum(is.na(.) | is.infinite(.)) == 0) %>%
colnames()Maybe, for some reason, you want to see the statistical significance of the correlation of each feature with Sale_Price when weighting by Lot_Area. I’ll calculate these across variables (and a random sample of 1500 observations) then plot them on a histogram.
set.seed(1234)
ames_data_features_example %>%
sample_n(1500) %>%
summarise_at(
.vars = features_keep[!(features_keep %in% c("Sale_Price", "Lot_Area"))],
.funs = ~weights::wtd.cor(., Sale_Price, weight = Lot_Area)[1]) %>%
gather() %>% # gather() is an older version of pivot_longer() w/ fewer parameters
ggplot(aes(x = value))+
geom_vline(xintercept = 0, colour = "lightgray", size = 2)+
geom_histogram()+
scale_x_continuous(labels = scales::comma)+
labs(title = "Distribution of correlations with Sale_Price",
subtitle = "Weighted by Lot Area",
x = "Weighted correlation coefficient")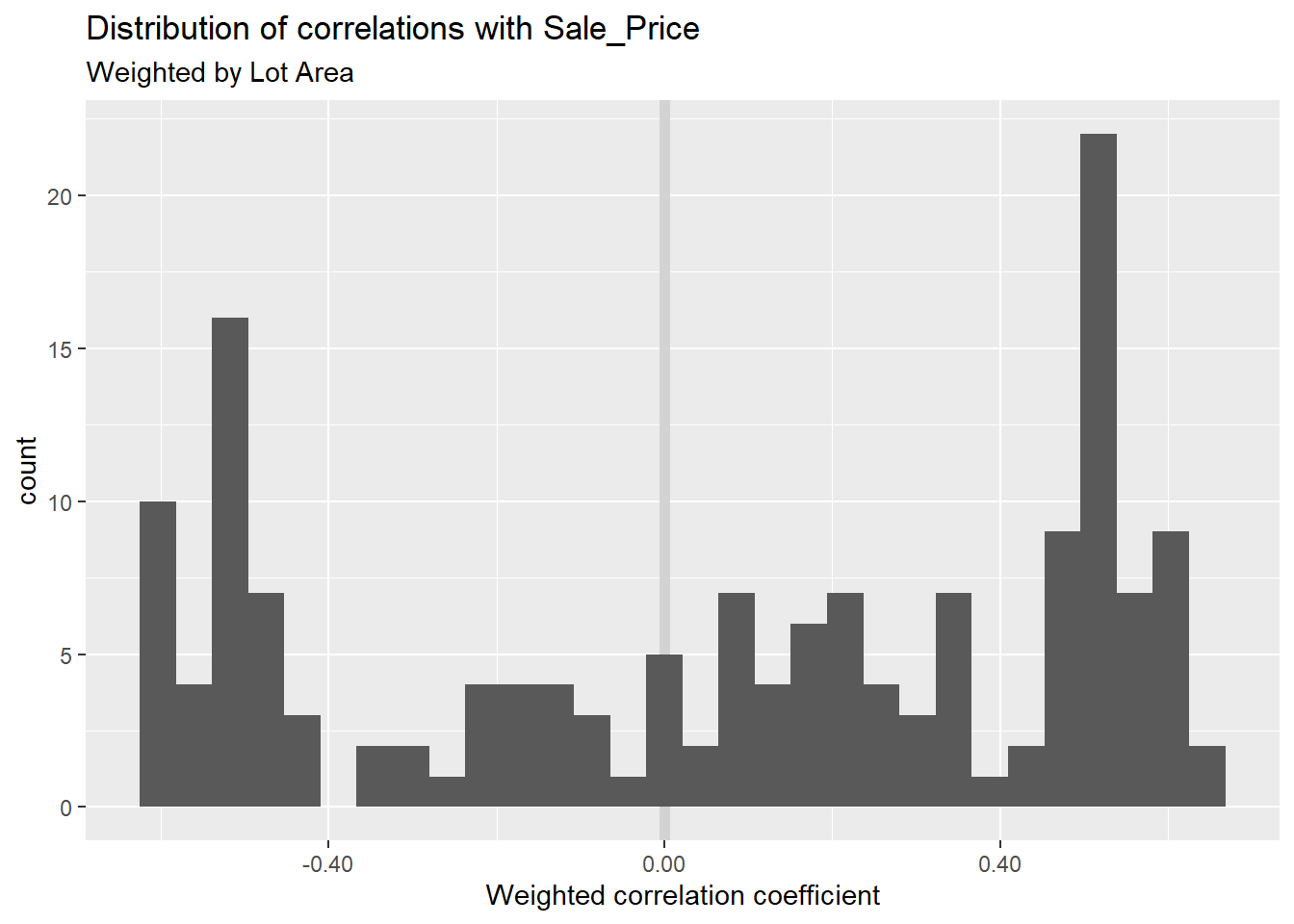
If doing predictive modeling or inference you may want to fit any transformations and analysis into a tidymodels pipeline or other framework. For some brief notes on this see Interactions example, tidymodels.
When is this approach inappropriate?
Combinatorial growth is very fast22. As you increase either the number of variables in your pool or the size of each set, you will quickly bump into computational limitations.
Tidyverse packages are optimized to be efficient. However operations with matrices or other specialized formats23 are generally faster24 than with dataframes/tibbles. If you are running into computational challenges but prefer to stick with a tidyverse aesthetic (which uses dataframes as a cornerstone), you might:
- Use heuristics to reduce the number of variables or operations you need to perform (e.g. take a sample, use a preliminary filter, a step-wise like iteration, etc.)
- Look for packages that abstract the storage and computationally heavy operations away25 and then return back an output in a convenient form26
- Improve the efficiency of your code (e.g. filter redundancies before rather than after expanding combinations)27
- Consider parralelizing
- Use matrices28
There is sometimes an urge to do everything in a tidy way, which is not necessary. For example, you could use an approach like the one I walk through to calculate pairwise correlations between each of your variables. However, the cor() function would do this much more efficiently if called on a matrix or traditional dataframe without list-columns (though you could also use the corrr package within the tidymodels suite which calls cor() in the back-end29).
However, for many operations…
- there may not be an efficient pairwise implementation available / accessible
- the slower computation may not matter or can be mitigated in some way
These situations30 are where the approach I walked through is most appropriate.
Appendix
Interactions example, tidymodels
A good example for creating and evaluating interaction terms31 is in The Brute-Force Approach to Identifying Predictive Interactions, Simple Screening section of Max Kuhn and Kjell Johnson’s (free) online book “Feature Engineering and Selection: A Practical Approach for Predictive Models”.
The source code shows another approach for combining variables. The author uses…
combn()to create all combinations of variable names which are then…- turned into formulas and passed into
recipes::step_interact(), specifying the new columns to be created32… - for each interaction term…
- in each associated model being evaluated
The example uses a mix of packages and styles and is not a purely tidy approach – tidymodels has also gone through a lot of development since “Feature Engineering and Selection…” was published in 201933. Section 11.2 on Greedy Search Methods, Simple Filters is also highly relevant.
Expand via join
You can take advantage of join34 behavior to create all possible row combinations. In this case, the output will be the same as shown when using expand() (except row order will be different).
left_join(mutate(df_lists, id = 1),
mutate(df_lists, id = 1) %>% rename_at(vars(-one_of("id")), paste0, "2")) %>%
select(-id)Nested tibbles
Creates list of tibbles rather than list of vectors – typically the first way lists as columns in dataframes is introduced.
ames_subset %>%
pivot_longer(everything(), names_to = "var", values_to = "list") %>%
group_by(var) %>%
nest()Pivot and then summarise
(Almost) equivalent to the example in I. Nest and pivot. Steps just run in a different order (row order will also be different).
ames_test %>%
pivot_longer(cols = everything(),
names_to = "var",
values_to = "vector") %>%
group_by(var) %>%
summarise_all(list)Gif for social media
AmesHousing::make_ames() %>%
select(Year = Year_Sold, Price = Sale_Price) %>%
# I.
group_by(Year) %>%
summarise(Price = list(Gr_Liv_Area)) %>%
ungroup() %>%
# II.
expand(nesting(Year, Price),
nesting(Year2 = Year, Price2 = Price)
) %>%
# III.
filter(Year != Year2) %>%
mutate(Years = map2_chr(.x = Year,
.y = Year2,
.f = c_sort_collapse)) %>%
distinct(Years, .keep_all = TRUE) %>%
select(-Years) %>%
#IV.
mutate(ks_test = map2(Price,
Price2,
stats::ks.test) %>% map_dbl("p.value")
)
Actual gif was created by embedding above code into a presentation and exporting it as a gif and then making a few minor edits.
Tweets
A few tweets as documentation of thinking. Many of these were added after publishing this post.
Original tweet + R bloggers tweet:
What is your #tidyverse (or other #rstats ) approach for doing arbitrary pairwise operations across variables? Mine is frequently something like:
— Bryan Shalloway (@brshallo) June 11, 2020
I. nest…
II. expand combos…
III. filter…
IV. map fun(s)…
…
I wrote a post walking through this: https://t.co/xRnRf5yh3m pic.twitter.com/Zvxey2gm3H
Tidy Pairwise Operations {https://t.co/mI5r2e5ttN} #rstats #DataScience
— R-bloggers (@Rbloggers) September 18, 2020
Tweet with link to gist of other example applying this approach:
@W_R_Chase alludes to using
— Bryan Shalloway (@brshallo) June 15, 2020expand()for a solution but takes a different approach. I wrote a short gist that fleshes in what atidyr::expand()approach to this problem could look like: https://t.co/agloPgJR1r (2/3)
Tweet about widyr:
Will add
— Bryan Shalloway (@brshallo) October 7, 2020widyrto my set of tools for tidy pairwise operations: https://t.co/NSxNC3nehK !
Seems to overlap some w/ tidymodels, egcorrr📦 (@thisisdaryn ) or could imagine widely_kmeans() as arecipe/embedstep…@drob any tips on when/how you use these in combination? https://t.co/dAsJtNW7Vo
Tweet with more efficient approach (for case when just combining multiple columns and returning output of equal number of rows, i.e. mutating rather than summarising):
How you can use
— Bryan Shalloway (@brshallo) October 15, 2020dplyr::mutate()to return a dataframe consisting of all combinations of arbitrary pairwise operations across a selection of columns: https://t.co/RxwtbmWqap #rstats #tidyverse … pic.twitter.com/UpJw0pGPUd
Tweet with approach using corrr
@mattwrkntn solution for grouped, pairwise operations in #rstats is excellent: https://t.co/wjbO4fRqxP . Just substitute in the new corrr::colpair_map for corrr::correlate and could use for any pairwise summarizing operation. pic.twitter.com/0Wf5KpQ4th
— Bryan Shalloway (@brshallo) January 30, 2021
Will focus on two-way example in this post, but could use similar methods to make more generalizable solution across n-way examples. If I were to do this, the code below would change. E.g.
- to use
pmap*()operations overmap2*()operations - I’d need to make some functions that make it so I can remove all the places where I have
varandvar2type column names hard-coded - Alternatively, I might shift approaches and make better use of
combn()
- to use
Though this “throw everything and the kitchen-sink” approach may not always be a good idea.↩︎
I’ve done this type of operation in a variety of ways. Sometimes without any really good reason as to why I used one approach or another. It isn’t completely clear (at least to me) the recommended way of doing these type of operations within the tidyverse – hence the diversity of my approaches in the past and deciding to document the typical steps in the approach I take… via writing this post.↩︎
Or the tidymodels implementation
corrr::correlate()in the corrr package.↩︎or is not in a style you prefer↩︎
I’ll also reference related approaches / small tweaks (putting those materials in the Appendix. This is by no means an exhaustive list (e.g. don’t have an example with a
forloop or with a%do%operator). The source code of my post on Ambiguous Absolute Value signs shows a related but more complex / messy approach on a combinatorics problem.↩︎In particular, the chapters on “Iteration” and “Many Models” in R for Data Science. I would also recommend Rebecca Barter’s Learn to purrr blog post.↩︎
The new
dplyr1.0.0. contains new functions that would have been potentially useful for several of these operations. I highly recommend checking these updates out in the various recent posts by Hadley Wickham. Some of the major updates (potentially relevant to the types of operations I’ll be discussing in my post):- new approach for across-column operations (replacing
_at(),_if(),_all()variants withacross()function) - brought-back rowwise operations
- emphasize ability to output tibbles / multiple columns in core
dplyrverbs. This is something I had only taken advantage of occassionally in the past (example), but will look to use more going forward.
- new approach for across-column operations (replacing
f I’d spotted this issue initially I’m not sure I would have written this post. However what this post offers is a more verbose treatment of the problem which may be useful for people newer to pairwise operations or the tidyverse.↩︎
For technical reasons, I also converted all integer types to doubles – was getting integer overflow problems in later operations before changing. Thread on integer overflow in R. In this post I’m not taking a disciplined approach to feature engineering. For example it may make sense to normalize the variables so that variable combinations would be starting on a similar scale. This could be done using
recipes::step_normalize()or with code likedplyr::mutate_all(df, ~(. - mean(.)) / sd(.)).↩︎Note that this part of the problem is one where I actually find using
tidyr::gather()easier – but I’ve been forcing myself to switch over to using thepivot_()functions overspread()andgather().↩︎The more common approach.↩︎
If your variables are across rows you are likely concerned with getting summary metrics rather than creating new features – as if your data is across rows there is nothing guaranteeing you have the same number of observations or that they are lined-up appropriately. If you are interested in creating new features, you should probably have first reshaped your data to ensure each column represented a variable.↩︎
As switching these would be more computationally efficient – see When is this approach inappropriate? for notes related to this. Switching the order here would suggest using approaches with the
combn()function.↩︎I.e. has the same output regardless of the order of the variables. E.g. multiplication or addition but not subtraction or division.↩︎
Function(s) that output vectors of length 1 (or less than length of input vectors).↩︎
Note that the pairwise implementation
psych::corr.test()could have been used on your original subsetted dataframe, see stack overflow thread.↩︎Function(s) that output vector of length equal to length of input vectors.↩︎
Did not print this output because cluttered-up page with so many column names.↩︎
Steps I - III and V & VI are essentially direct copies of the code above. The approach I took with Step IV may take more effort to follow as it requires understanding a little
rlangand could likely have been done more simply.↩︎Must have two vectors as input, but do not need to be infix functions.↩︎
Non-technical article discussing combinatorial explosion in context of company user growth targets: Exponential Growth Isn’t Cool. Combinatorial Growth Is..↩︎
E.g. data.table dataframes↩︎
Hence, if you are doing operations across combinations of lots of variables it may not make sense to do the operations directly within dataframes.↩︎
Much (if not most) of the
tidyverse(and the R programming language generally) is about creating a smooth interface between the analyst/scientist and the back-end complexity of the operations they are performing. Projects like sparklyr, DBI, reticulate, tidymodels, and brms (to name a few) represent cases where this interface role of R is most apparent.↩︎For tidyverse packages, this is often returned into or in the form of a dataframe.↩︎
Could make better use of
combn()function to help.↩︎Depending on the complexity may just need to brush-up on your linear algebra.↩︎
corrrcan also be used to run the operation on databases that may have larger data than you could fit on your computer.↩︎Likely more common for many, if not most, analysts and data scientists.↩︎
I.e. multiplying two variables together↩︎
Created upon the recipe being baked or juiced – if you have not checked it out, recipes is AWESOME!↩︎
Maybe at a future date I’ll make a post writing out the example here using the newer approaches now available in
tidymodels. Gist ofcombn_ttible()… starting place for if I ever get to that write-up.↩︎Could also have used
right_join()orfull_join().↩︎